Tutorials
Compiling Deepchem Torch Models ¶
Deep Learning models typically involve millions or even billions of parameters (as in the case of LLMs) that need to be fine-tuned through an iterative training processes. During training, these models process vast amounts of data to learn patterns and features effectively. This data-intensive nature, combined with the computational complexity of operations like matrix multiplications and backpropagation, leads to lengthy training times that can span days, weeks, or even months on standard hardware. Additionally, the need for multiple training runs to experiment with the different model and hyperparameter configurations further extends the overall development time.
Effective optimization techniques can significantly reduce training times, lower computational costs, and improve model performance. This makes optimization particularly crucial in research and industrial settings where faster iterations can accelerate scientific discoveries, product development, and the deployment of AI solutions. Moreover, as models grow larger and more sophisticated, optimization plays a vital role in making advanced AI accessible and practical for a wider range of applications and environments.
To address the need for optimization of Deep Larning models and as an improvement over existing methods, PyTorch introduced the
torch.compile()
function in PyTorch 2.0 to allow faster training and inference of the models.
torch.compile()
works by compiling PyTorch code into optimised kernels using a JIT(Just in Time) compiler. Different models show varying levels of improvement in run times depending on their architecture and batch size when compiled. Compared to existing methods like
TorchScript
or
FX tracing
,
compile()
also offers advantages such as the ability to handle arbitrary Python code and conditional graph-breaking flow of the inputs to the models. This allows
compile()
to work with minimal or no code modification to the model.
DeepChem has builtin support for compiling PyTorch models using
torch.compile()
and using this feature, users can efficiently run PyTorch models and achieve significant performance gains. This tutorial contains the steps for compiling DeepChem PyTorch models, benchmarking and evaluating their performance with the uncompiled models.
NOTE: DeepChem contains many models with varying architecture and complexity. Not all models will show significant improvements in run times when compiled. It is recommended to test the models with and without compilation to determine the performance improvements.
Colab ¶
This tutorial and the rest in this sequence can be done in Google colab. If you'd like to open this notebook in colab, you can use the following link.
![]()
Compilation Process ¶
This section gives an introductory explanation about the compilation process of PyTorch models and assumes prior knowledge about forward pass, backward pass and computational graphs in neural networks. If you're unfamiliar with these concepts, you can refer to these slides for a basic understanding. Alternatively, you can proceed to the next section to learn how to compile and benchmark DeepChem models without delving into the internal details of the compilation process.
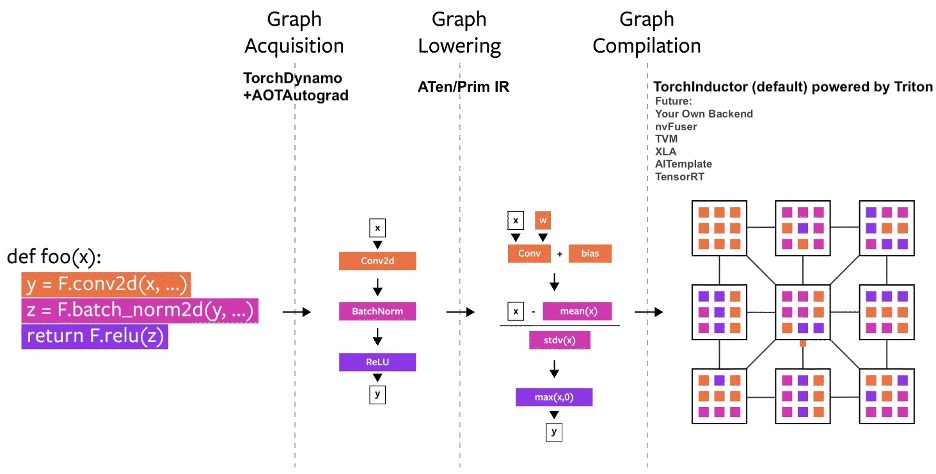
Image taken from PyTorch2.0 Introductory Blog
The compilation process is split into multiple steps which uses many new technologies that were introduced in PyTorch 2.0. The process is as follows:
-
Graph Acquisition: During the compilation process, TorchDynamo and AOTAutograd are used for capturing the forward and backward pass graphs respectively. AOTAutograd allows the backward graph to be captured ahead of time without needing a backward pass to be performed.
-
Graph Lowering: The captured graph that could be composed of the 2000+ PyTorch operators is lowered into a collection of ~250 Prim and ~750 ATen operators.
-
Graph Compilation: In this step optimised low-level kernels are generated for the target accelerator using a suitable backend compiler. TorchInductor is the default backend compiler used for this purpose.
Deepchem uses the
torch.compile()
function that implements all the above steps internally to compile the models. The compiled model can be used for training, evaluation and inference.
For more information on the compilation process, refer to PyTorch2.0 Introductory Blog that does a deep dive into the compilation process, technical decisions and future features for the compile function. You can also refer to the Huggingface blog, Optimize inference using torch.compile() that benchmarks many common PyTorch models and shows the performance improvements when compiled.
Compiling Models ¶
The compile function is only available in DeepChem for models that use PyTorch as the backend (i.e inherits
TorchModel
class). You can see the complete list of models that are available in DeepChem and their backends in the DeepChem Documentation
here
.
This tutorial contains the steps to load a DeepChem model, compile it and evaluate the performance improvements when compiled for both training and inference. Refer to the documentation of DeepChem's compile function to read more about the different parameters you can pass to the function and their usage.
If you just want to compile the model, you can add the line
model.compile()
after initialising the model. You
DO NOT
have to make any changes to the rest of your code.
Some of the things to keep in mind when compiling models are:
-
Selecting the right mode: The modes can be
default,reduce-overhead,max-autotuneormax-autotune-no-cudagraphs. Out of thisreduce-overheadandmax-autotunemodes requirestritonto be installed. Refer to the PyTorch docs ontorch.compilefor more information on the modes. -
Setting
fullgraphparameter: If True (defaultFalse),torch.compilewill require that the entire function be capturable into a single graph. If this is not possible (that is, if there are graph breaks), then the function will raise an error. -
Experimenting with different parameter configuration: Different parameter configurations can give different speedups based on the model, batch size and the device used for training/inference. Experiment with a few parameter combinations to check which one gives better results.
In this tutorial, we will be using DMPNN model and Freesolv Dataset for training and inference of the models.
!pip install --pre deepchem
!pip install torch_geometric #required for DMPNN model
!pip install triton #required for reduce-overhead mode
Collecting deepchem
Downloading deepchem-2.8.1.dev20240624214143-py3-none-any.whl (1.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 6.9 MB/s eta 0:00:00
Requirement already satisfied: joblib in /usr/local/lib/python3.10/dist-packages (from deepchem) (1.4.2)
Requirement already satisfied: numpy<2 in /usr/local/lib/python3.10/dist-packages (from deepchem) (1.25.2)
Requirement already satisfied: pandas in /usr/local/lib/python3.10/dist-packages (from deepchem) (2.0.3)
Requirement already satisfied: scikit-learn in /usr/local/lib/python3.10/dist-packages (from deepchem) (1.2.2)
Requirement already satisfied: sympy in /usr/local/lib/python3.10/dist-packages (from deepchem) (1.12.1)
Requirement already satisfied: scipy>=1.10.1 in /usr/local/lib/python3.10/dist-packages (from deepchem) (1.11.4)
Collecting rdkit (from deepchem)
Downloading rdkit-2024.3.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (35.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 35.1/35.1 MB 14.6 MB/s eta 0:00:00
Requirement already satisfied: python-dateutil>=2.8.2 in /usr/local/lib/python3.10/dist-packages (from pandas->deepchem) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.10/dist-packages (from pandas->deepchem) (2023.4)
Requirement already satisfied: tzdata>=2022.1 in /usr/local/lib/python3.10/dist-packages (from pandas->deepchem) (2024.1)
Requirement already satisfied: Pillow in /usr/local/lib/python3.10/dist-packages (from rdkit->deepchem) (9.4.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.10/dist-packages (from scikit-learn->deepchem) (3.5.0)
Requirement already satisfied: mpmath<1.4.0,>=1.1.0 in /usr/local/lib/python3.10/dist-packages (from sympy->deepchem) (1.3.0)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.8.2->pandas->deepchem) (1.16.0)
Installing collected packages: rdkit, deepchem
Successfully installed deepchem-2.8.1.dev20240624214143 rdkit-2024.3.1
Collecting torch_geometric
Downloading torch_geometric-2.5.3-py3-none-any.whl (1.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 10.8 MB/s eta 0:00:00
Requirement already satisfied: tqdm in /usr/local/lib/python3.10/dist-packages (from torch_geometric) (4.66.4)
Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from torch_geometric) (1.25.2)
Requirement already satisfied: scipy in /usr/local/lib/python3.10/dist-packages (from torch_geometric) (1.11.4)
Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from torch_geometric) (2023.6.0)
Requirement already satisfied: jinja2 in /usr/local/lib/python3.10/dist-packages (from torch_geometric) (3.1.4)
Requirement already satisfied: aiohttp in /usr/local/lib/python3.10/dist-packages (from torch_geometric) (3.9.5)
Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from torch_geometric) (2.31.0)
Requirement already satisfied: pyparsing in /usr/local/lib/python3.10/dist-packages (from torch_geometric) (3.1.2)
Requirement already satisfied: scikit-learn in /usr/local/lib/python3.10/dist-packages (from torch_geometric) (1.2.2)
Requirement already satisfied: psutil>=5.8.0 in /usr/local/lib/python3.10/dist-packages (from torch_geometric) (5.9.5)
Requirement already satisfied: aiosignal>=1.1.2 in /usr/local/lib/python3.10/dist-packages (from aiohttp->torch_geometric) (1.3.1)
Requirement already satisfied: attrs>=17.3.0 in /usr/local/lib/python3.10/dist-packages (from aiohttp->torch_geometric) (23.2.0)
Requirement already satisfied: frozenlist>=1.1.1 in /usr/local/lib/python3.10/dist-packages (from aiohttp->torch_geometric) (1.4.1)
Requirement already satisfied: multidict<7.0,>=4.5 in /usr/local/lib/python3.10/dist-packages (from aiohttp->torch_geometric) (6.0.5)
Requirement already satisfied: yarl<2.0,>=1.0 in /usr/local/lib/python3.10/dist-packages (from aiohttp->torch_geometric) (1.9.4)
Requirement already satisfied: async-timeout<5.0,>=4.0 in /usr/local/lib/python3.10/dist-packages (from aiohttp->torch_geometric) (4.0.3)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/dist-packages (from jinja2->torch_geometric) (2.1.5)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->torch_geometric) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->torch_geometric) (3.7)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->torch_geometric) (2.0.7)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->torch_geometric) (2024.6.2)
Requirement already satisfied: joblib>=1.1.1 in /usr/local/lib/python3.10/dist-packages (from scikit-learn->torch_geometric) (1.4.2)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.10/dist-packages (from scikit-learn->torch_geometric) (3.5.0)
Installing collected packages: torch_geometric
Successfully installed torch_geometric-2.5.3
Requirement already satisfied: triton in /usr/local/lib/python3.10/dist-packages (2.3.0)
Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from triton) (3.15.3)
import torch
import datetime
import numpy as np
import deepchem as dc
import matplotlib.pyplot as plt
WARNING:deepchem.feat.molecule_featurizers.rdkit_descriptors:No normalization for SPS. Feature removed! WARNING:deepchem.feat.molecule_featurizers.rdkit_descriptors:No normalization for AvgIpc. Feature removed! WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/tensorflow/python/util/deprecation.py:588: calling function (from tensorflow.python.eager.polymorphic_function.polymorphic_function) with experimental_relax_shapes is deprecated and will be removed in a future version. Instructions for updating: experimental_relax_shapes is deprecated, use reduce_retracing instead WARNING:deepchem.models.torch_models:Skipped loading modules with pytorch-geometric dependency, missing a dependency. No module named 'dgl' WARNING:deepchem.models:Skipped loading modules with pytorch-lightning dependency, missing a dependency. No module named 'lightning' WARNING:deepchem.models:Skipped loading some Jax models, missing a dependency. No module named 'haiku'
torch._dynamo.config.cache_size_limit = 64
tasks, datasets, transformers = dc.molnet.load_freesolv(featurizer=dc.feat.DMPNNFeaturizer(), splitter='random')
train_dataset, valid_dataset, test_dataset = datasets
len(train_dataset), len(valid_dataset), len(test_dataset)
model = dc.models.DMPNNModel()
The below line is the only addition you have to make to the code for compiling the model. You can pass in the other arguments too to the
compile()
function if they are required.
model.compile()
/usr/lib/python3.10/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock. self.pid = os.fork()
model.fit(train_dataset, nb_epoch=10)
metrics = [dc.metrics.Metric(dc.metrics.mean_squared_error)]
print(f"Training MSE: {model.evaluate(train_dataset, metrics=metrics)}")
print(f"Validation MSE: {model.evaluate(valid_dataset, metrics=metrics)}")
print(f"Test MSE: {model.evaluate(test_dataset, metrics=metrics)}")
Training MSE: {'mean_squared_error': 0.04699941161198689}
Validation MSE: {'mean_squared_error': 0.18010469643557037}
Test MSE: {'mean_squared_error': 0.043559911545479245}
Benchmarking model Speedups ¶
This section contains the steps for benchmarking the performance of models after compilation process for both training and inference. We are using the same model(DMPNN) and dataset(FreSolv) in this section too. The steps for compilation and benchmarking is same for other models as well.
To account for the initial performance overhead of kernel compilation in compiled models, median values are employed as the performance metric throughout the tutorial for calculating speedup.
The below two functions,
time_torch_function
and
get_time_track_callback
can be used for tracking the time taken for inference and training respectively.
The implementation of
time_torch_function
is taken from the PyTorch official
torch.compile
tutorial
here
.
We use
get_time_track_callback
to make a callback that can track the time taken for each batch during training as DeepChem does not provide a direct way to track the time taken per batch during training. We can use this callback by passing it as an argument to
model.fit()
function.
def time_torch_function(fn):
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
result = fn()
end.record()
torch.cuda.synchronize()
return result, start.elapsed_time(end) / 1000
track_dict = {}
prev_time_dict = {}
def get_time_track_callback(track_dict, track_name, track_interval):
track_dict[track_name] = []
prev_time_dict[track_name] = datetime.datetime.now()
def callback(model, step):
if step % track_interval == 0:
elapsed_time = datetime.datetime.now() - prev_time_dict[track_name]
track_dict[track_name].append(elapsed_time.total_seconds())
prev_time_dict[track_name] = datetime.datetime.now()
return callback
Tracking Training Time ¶
model = dc.models.DMPNNModel()
model_compiled = dc.models.DMPNNModel()
model_compiled.compile(mode='reduce-overhead')
track_interval = 20
eager_dict_name = "eager_train"
compiled_dict_name = "compiled_train"
eager_train_callback = get_time_track_callback(track_dict, eager_dict_name, track_interval)
model.fit(train_dataset, nb_epoch=10, callbacks=[eager_train_callback])
compiled_train_callback = get_time_track_callback(track_dict, compiled_dict_name, track_interval)
model_compiled.fit(train_dataset, nb_epoch=10, callbacks=[compiled_train_callback])
0.06506308714548746
eager_train_times = track_dict[eager_dict_name]
compiled_train_times = track_dict[compiled_dict_name]
print(f"Eager Times (first 15): {[f'{t:.3f}' for t in eager_train_times[:15]]}")
print(f"Compiled Times (first 15): {[f'{t:.3f}' for t in compiled_train_times[:15]]}")
print(f"Total Eager Time: {sum(eager_train_times)}")
print(f"Total Compiled Time: {sum(compiled_train_times)}")
print(f"Eager Median: {np.median(eager_train_times)}")
print(f"Compiled Median: {np.median(compiled_train_times)}")
print(f"Median Speedup: {((np.median(eager_train_times) / np.median(compiled_train_times)) - 1) * 100:.2f}%")
Eager Times (first 15): ['1.067', '0.112', '0.093', '0.097', '0.102', '0.098', '0.095', '0.097', '0.099', '0.098', '0.097', '0.103', '0.095', '0.103', '0.096'] Compiled Times (first 15): ['29.184', '21.463', '11.503', '13.742', '1.951', '5.595', '7.568', '8.201', '7.761', '0.083', '7.087', '2.421', '1.961', '0.079', '1.948'] Total Eager Time: 29.176121000000023 Total Compiled Time: 243.32460400000022 Eager Median: 0.100118 Compiled Median: 0.0843535 Median Speedup: 18.69%
x_vals = np.arange(1, len(eager_train_times) + 1) * track_interval
plt.plot(x_vals, eager_train_times, label="Eager")
plt.plot(x_vals, compiled_train_times, label="Compiled")
plt.yscale('log', base= 10)
plt.ylabel('Time (s)')
plt.xlabel('Batch Iteration')
plt.legend()
plt.show()

Looking at the graph, there is a significant difference in the time taken for the compiled and uncompiled versions of the model for the starting many steps. After that the time taken by the compiled model stabilises below the uncompiled model. This is because the compilation is done JIT when the model is first run and the optimized kernels are generated after a few passes.
Tracking Inference Time ¶
model = dc.models.DMPNNModel()
model_compiled = dc.models.DMPNNModel()
model_compiled.compile(mode='reduce-overhead')
iters = 100
eager_predict_times = []
compiled_predict_times = []
for i in range(iters):
for X, y, w, ids in test_dataset.iterbatches(64, pad_batches=True):
with torch.no_grad():
_, eager_time = time_torch_function(lambda: model.predict_on_batch(X))
_, compiled_time = time_torch_function(lambda: model_compiled.predict_on_batch(X))
eager_predict_times.append(eager_time)
compiled_predict_times.append(compiled_time)
print(f"Eager Times (first 15): {[f'{t:.3f}' for t in eager_predict_times[:15]]}")
print(f"Compiled Times (first 15): {[f'{t:.3f}' for t in compiled_predict_times[:15]]}")
print(f"Total Eager Time: {sum(eager_predict_times)}")
print(f"Total Compiled Time: {sum(compiled_predict_times)}")
print(f"Eager Median: {np.median(eager_predict_times)}")
print(f"Compiled Median: {np.median(compiled_predict_times)}")
print(f"Median Speedup: {((np.median(eager_predict_times) / np.median(compiled_predict_times)) - 1) * 100:.2f}%")
Eager Times (first 15): ['0.170', '0.173', '0.161', '0.160', '0.160', '0.165', '0.158', '0.159', '0.164', '0.161', '0.162', '0.154', '0.159', '0.161', '0.162'] Compiled Times (first 15): ['47.617', '1.168', '26.927', '0.127', '0.134', '0.138', '0.130', '0.130', '0.133', '0.125', '0.130', '0.132', '0.139', '0.128', '0.133'] Total Eager Time: 35.297711242675796 Total Compiled Time: 104.20891365814221 Eager Median: 0.1617226104736328 Compiled Median: 0.1332385482788086 Median Speedup: 21.38%
plt.plot(eager_predict_times, label= "Eager")
plt.plot(compiled_predict_times, label= "Compiled")
plt.ylabel('Time (s)')
plt.xlabel('Batch Iteration')
plt.yscale('log', base= 10)
plt.legend()
<matplotlib.legend.Legend at 0x7c7a040c9c30>

As with the results we got training, the first few runs for inference also takes significantly more time due to the same reason as mentioned before.
Congratulations! Time to join the Community! ¶
Congratulations on completing this tutorial notebook! If you enjoyed working through the tutorial, and want to continue working with DeepChem, we encourage you to finish the rest of the tutorials in this series. You can also help the DeepChem community in the following ways: