Tutorials
Tutorial: ChemBERTa: Large-Scale Self-Supervised Pretraining for Molecular Property Prediction using a Smiles Tokenization Strategy ¶

By Seyone Chithrananda ( Twitter )
Deep learning for chemistry and materials science remains a novel field with lots of potiential. However, the popularity of transfer learning based methods in areas such as natural language processing (NLP) and computer vision have not yet been effectively developed in computational chemistry + machine learning. Using HuggingFace's suite of models and the ByteLevel tokenizer, we are able to train a large-transformer model, RoBERTa, on a large corpus of 10,000,000 SMILES strings from a commonly known benchmark chemistry dataset, PubChem.
Training RoBERTa over 10 epochs, the model achieves a pretty good loss of 0.198, and may likely continue to converge if trained for a larger number of epochs. The model can predict masked/corrupted tokens within a SMILES sequence/molecule, allowing for variants of a molecule within discoverable chemical space to be predicted.
By applying the representations of functional groups and atoms learned by the model, we can try to tackle problems of toxicity, solubility, drug-likeness, and synthesis accessibility on smaller datasets using the learned representations as features for graph convolution and attention models on the graph structure of molecules, as well as fine-tuning of BERT. Finally, we propose the use of attention visualization as a helpful tool for chemistry practitioners and students to quickly identify important substructures in various chemical properties.
Additionally, visualization of the attention mechanism have been seen through previous research as incredibly valuable towards chemical reaction classification. The applications of open-sourcing large-scale transformer models such as RoBERTa with HuggingFace may allow for the acceleration of these individual research directions.
A link to a repository which includes the training, uploading and evaluation notebook (with sample predictions on compounds such as Remdesivir) can be found here . All of the notebooks can be copied into a new Colab runtime for easy execution. This repository will be updated with new features, such as attention visualization, easier benchmarking infrastructure, and more. The work behind this tutorial has been published on Arxiv , and was accepted for a poster presentation at NeurIPS 2020's ML for Molecules Workshop .
For the sake of this tutorial, we'll be fine-tuning a pre-trained ChemBERTa on a small-scale molecule dataset, Clintox, to show the potiential and effectiveness of HuggingFace's NLP-based transfer learning applied to computational chemistry. Output for some cells are purposely cleared for readability, so do not worry if some output messages for your cells differ!
In short, there are three major components we'll be going over in this notebook.
- Masked token inference predictions on SMILES strings
- Attention visualizaiton of the PubChem-10M model
- Fine-tuninhg BPE-ChemBERTa and Smiles-Tokenizer ChemBERTa model's on the CLintox toxicity dataset.
Don't worry if you aren't familiar with some of these terms. We will explain them later in the tutorial!
If you're looking to dive deeper, check out the poster here .
Colab ¶
This tutorial and the rest in this sequence are designed to be done in Google colab. If you'd like to open this notebook in colab, you can use the following link.
![]()
Setup ¶
To run DeepChem within Colab, you'll need to run the following cell of installation commands. This will take about 5 minutes to run to completion and install your environment.
!curl -Lo conda_installer.py https://raw.githubusercontent.com/deepchem/deepchem/master/scripts/colab_install.py
import conda_installer
conda_installer.install()
!/root/miniconda/bin/conda info -e
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 3501 100 3501 0 0 16995 0 --:--:-- --:--:-- --:--:-- 16995
add /root/miniconda/lib/python3.7/site-packages to PYTHONPATH python version: 3.7.10 remove current miniconda fetching installer from https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh done installing miniconda to /root/miniconda done installing rdkit, openmm, pdbfixer added omnia to channels added conda-forge to channels done conda packages installation finished!
# conda environments: # base * /root/miniconda
!pip install --pre deepchem
import deepchem
deepchem.__version__
Requirement already satisfied: deepchem in /usr/local/lib/python3.7/dist-packages (2.5.0) Requirement already satisfied: pandas in /usr/local/lib/python3.7/dist-packages (from deepchem) (1.1.5) Requirement already satisfied: scipy in /usr/local/lib/python3.7/dist-packages (from deepchem) (1.4.1) Requirement already satisfied: scikit-learn in /usr/local/lib/python3.7/dist-packages (from deepchem) (0.22.2.post1) Requirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from deepchem) (1.19.5) Requirement already satisfied: joblib in /usr/local/lib/python3.7/dist-packages (from deepchem) (1.0.1) Requirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.7/dist-packages (from pandas->deepchem) (2.8.1) Requirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.7/dist-packages (from pandas->deepchem) (2018.9) Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.7.3->pandas->deepchem) (1.15.0)
wandb: WARNING W&B installed but not logged in. Run `wandb login` or set the WANDB_API_KEY env variable. wandb: WARNING W&B installed but not logged in. Run `wandb login` or set the WANDB_API_KEY env variable.
'2.5.0'
from rdkit import Chem
We want to install NVIDIA's Apex tool, for the training pipeline used by
simple-transformers
and Weights and Biases. This package enables us to use 16-bit training, mixed precision, and distributed training without any changes to our code. Generally GPUs are good at doing 32-bit(single precision) math, not at 16-bit(half) nor 64-bit(double precision). Therefore traditionally deep learning model trainings are done in 32-bit. By switching to 16-bit, we’ll be using half the memory and theoretically less computation at the expense of the available number range and precision. However, pure 16-bit training creates a lot of problems for us (imprecise weight updates, gradient underflow and overflow).
Mixed precision training, with Apex, alleviates these problems
.
We will be installing
simple-transformers
, a library which builds ontop of HuggingFace's
transformers
package specifically for fine-tuning ChemBERTa.
!git clone https://github.com/NVIDIA/apex
!cd /content/apex
!pip install -v --no-cache-dir /content/apex
!pip install transformers
!pip install simpletransformers
!pip install wandb
!cd ..
import sys
!test -d bertviz_repo && echo "FYI: bertviz_repo directory already exists, to pull latest version uncomment this line: !rm -r bertviz_repo"
# !rm -r bertviz_repo # Uncomment if you need a clean pull from repo
!test -d bertviz_repo || git clone https://github.com/jessevig/bertviz bertviz_repo
if not 'bertviz_repo' in sys.path:
sys.path += ['bertviz_repo']
!pip install regex
FYI: bertviz_repo directory already exists, to pull latest version uncomment this line: !rm -r bertviz_repo Requirement already satisfied: regex in /usr/local/lib/python3.7/dist-packages (2019.12.20)
We're going to clone an auxillary repository, bert-loves-chemistry, which will enable us to use the MolNet dataloader for ChemBERTa, which automatically generates scaffold splits on any MoleculeNet dataset!
!git clone https://github.com/seyonechithrananda/bert-loves-chemistry.git
fatal: destination path 'bert-loves-chemistry' already exists and is not an empty directory.
!nvidia-smi
Thu Mar 18 14:48:19 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.56 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... Off | 00000000:00:04.0 Off | 0 |
| N/A 31C P0 26W / 250W | 0MiB / 16280MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Now, to ensure our model demonstrates an understanding of chemical syntax and molecular structure, we'll be testing it on predicting a masked token/character within the SMILES molecule for benzene.
# Test if NVIDIA apex training tool works
from apex import amp
What is a tokenizer? ¶
A tokenizer is in charge of preparing the inputs for a natural language processing model. For many scientific applications, it is possible to treat inputs as “words”/”sentences” and use NLP methods to make meaningful predictions. For example, SMILES strings or DNA sequences have grammatical structure and can be usefully modeled with NLP techniques. DeepChem provides some scientifically relevant tokenizers for use in different applications. These tokenizers are based on those from the Huggingface transformers library (which DeepChem tokenizers inherit from).
The base classes PreTrainedTokenizer and PreTrainedTokenizerFast in HuggingFace implements the common methods for encoding string inputs in model inputs and instantiating/saving python tokenizers either from a local file or directory or from a pretrained tokenizer provided by the library (downloaded from HuggingFace’s AWS S3 repository).
PreTrainedTokenizer (transformers.PreTrainedTokenizer) ) thus implements the main methods for using all the tokenizers:
-
Tokenizing (spliting strings in sub-word token strings), converting tokens strings to ids and back, and encoding/decoding (i.e. tokenizing + convert to integers),
-
Adding new tokens to the vocabulary in a way that is independant of the underlying structure (BPE, SentencePiece…),
-
Managing special tokens like mask, beginning-of-sentence, etc tokens (adding them, assigning them to attributes in the tokenizer for easy access and making sure they are not split during tokenization)
The default tokenizer used by ChemBERTa, is a Byte-Pair-Encoder (BPE). It is a hybrid between character and word-level representations, which allows for the handling of large vocabularies in natural language corpora. Motivated by the intuition that rare and unknown words can often be decomposed into multiple known subwords, BPE finds the best word segmentation by iteratively and greedily merging frequent pairs of characters.
First, lets load the model's Byte-Pair Encoding tokenizer, and model, and setup a Huggingface pipeline for masked tokeni prediction.
from transformers import AutoModelForMaskedLM, AutoTokenizer, pipeline, RobertaModel, RobertaTokenizer
from bertviz import head_view
model = AutoModelForMaskedLM.from_pretrained("seyonec/PubChem10M_SMILES_BPE_450k")
tokenizer = AutoTokenizer.from_pretrained("seyonec/PubChem10M_SMILES_BPE_450k")
fill_mask = pipeline('fill-mask', model=model, tokenizer=tokenizer)
Downloading: 0%| | 0.00/515 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/336M [00:00<?, ?B/s]
Downloading: 0%| | 0.00/165k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/101k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/772 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/62.0 [00:00<?, ?B/s]
What is a transformer model? ¶
Previously, we spoke about the attention mechanism in modern deep learning models. Attention is a concept that helped improve the performance of neural machine translation applications. The Transformer is a model that uses attention to boost the speed with which these models can be trained.
With the emergence of BERT by Google AI in 2018, transformers have quickly shot to the top of emerging deep learning methods, outperforming Neural Machine Translation models such as seq2seq and recurrent neural networks at dozens of tasks.
The biggest benefit, however, comes from how The Transformer lends itself to efficient pre-training . Using the same pre-training procedure used by RoBERTa, a follow-up work of BERT, which masks 15% of the tokens, we mask 15% of the tokens in each SMILES string and assign a maximum sequence length of 256 characters.
The model then learns to predict masked tokens consisting of atoms and functional groups , or specific groups of atoms within molecules which have their own characteristic properties. Through this, the model learns the relevant molecular context for transferable tasks, such as property prediction.
ChemBERTa employs a bidirectional training context to learn context-aware representations of the PubChem 10M dataset, downloadable through MoleculeNet for self-supervised pre-training ( link ). Our variant of the BERT transformer uses 12 attention heads and 6 layers, resulting in 72 distinct attention mechanisms.
The Transformer was proposed in the paper Attention is All You Need.
Now, to ensure our the ChemBERTa model demonstrates an understanding of chemical syntax and molecular structure, we'll be testing it on predicting a masked token/character within the SMILES molecule for benzene. Using the Huggingface pipeline we initialized earlier we can fetch a list of the model's predictions by confidence score:
smiles_mask = "C1=CC=CC<mask>C1"
smiles = "C1=CC=CC=C1"
masked_smi = fill_mask(smiles_mask)
for smi in masked_smi:
print(smi)
{'sequence': 'C1=CC=CC=C1', 'score': 0.9755934476852417, 'token': 33, 'token_str': '='}
{'sequence': 'C1=CC=CC#C1', 'score': 0.020923888310790062, 'token': 7, 'token_str': '#'}
{'sequence': 'C1=CC=CC1C1', 'score': 0.0007658962858840823, 'token': 21, 'token_str': '1'}
{'sequence': 'C1=CC=CC2C1', 'score': 0.0004129768058191985, 'token': 22, 'token_str': '2'}
{'sequence': 'C1=CC=CC=[C1', 'score': 0.00025319133419543505, 'token': 352, 'token_str': '=['}
Here, we get some interesting results. The final branch,
C1=CC=CC=C1
, is a benzene ring. Since its a pretty common molecule, the model is easily able to predict the final double carbon bond with a score of 0.98. Let's get a list of the top 5 predictions (including the target, Remdesivir), and visualize them (with a highlighted focus on the beginning of the final benzene-like pattern). To visualize them, we'll be using the RDKit cheminoformatics package we installed earlier, specifically the
rdkit.chem.Draw
module.
import torch
import rdkit
import rdkit.Chem as Chem
from rdkit.Chem import rdFMCS
from matplotlib import colors
from rdkit.Chem import Draw
from rdkit.Chem.Draw import MolToImage
from PIL import Image
def get_mol(smiles):
mol = Chem.MolFromSmiles(smiles)
if mol is None:
return None
Chem.Kekulize(mol)
return mol
def find_matches_one(mol,submol):
#find all matching atoms for each submol in submol_list in mol.
match_dict = {}
mols = [mol,submol] #pairwise search
res=rdFMCS.FindMCS(mols) #,ringMatchesRingOnly=True)
mcsp = Chem.MolFromSmarts(res.smartsString)
matches = mol.GetSubstructMatches(mcsp)
return matches
#Draw the molecule
def get_image(mol,atomset):
hcolor = colors.to_rgb('green')
if atomset is not None:
#highlight the atoms set while drawing the whole molecule.
img = MolToImage(mol, size=(600, 600),fitImage=True, highlightAtoms=atomset,highlightColor=hcolor)
else:
img = MolToImage(mol, size=(400, 400),fitImage=True)
return img
sequence = f"C1=CC=CC={tokenizer.mask_token}1"
substructure = "CC=CC"
image_list = []
input = tokenizer.encode(sequence, return_tensors="pt")
mask_token_index = torch.where(input == tokenizer.mask_token_id)[1]
token_logits = model(input)[0]
mask_token_logits = token_logits[0, mask_token_index, :]
top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
for token in top_5_tokens:
smi = (sequence.replace(tokenizer.mask_token, tokenizer.decode([token])))
print (smi)
smi_mol = get_mol(smi)
substructure_mol = get_mol(substructure)
if smi_mol is None: # if the model's token prediction isn't chemically feasible
continue
Draw.MolToFile(smi_mol, smi+".png")
matches = find_matches_one(smi_mol, substructure_mol)
atomset = list(matches[0])
img = get_image(smi_mol, atomset)
img.format="PNG"
image_list.append(img)
C1=CC=CC=CC1 C1=CC=CC=CCC1 C1=CC=CC=CN1 C1=CC=CC=CCCC1 C1=CC=CC=CCO1
from IPython.display import Image
for img in image_list:
display(img)





As we can see above, 5 out of 5 of the model's MLM predictions are chemically valid. Overall, the model seems to understand syntax with a pretty decent degree of certainity.
However, further training on a more specific dataset (say leads for a specific target) may generate a stronger chemical transformer model. Let's now fine-tune our model on a dataset of our choice, ClinTox. You can run ChemBERTa on any MoleculeNet dataset, but for the sake of convinience, we will use ClinTox as it is small and trains quickly.
What is attention? ¶
Previously, recurrent models struggled with generating a fixed-length vector for large sequences, leading to deteriorating performance as the length of an input sequence increased.
Attention is, to some extent, motivated by how we pay visual attention to different regions of our vision or how we correlate words in a sentence. Human visual attention allows us to focus on a certain subregion with a higher focus while perceiving the surrounding image in with a lower focus, and then adjust the focal point.
Similarly, we can explain the relationship between words in one sentence or close context. When we see “eating”, we expect to read a food word very soon. The color term describes the food, but probably not as directly as “eating” does:

The attention mechanism extends on the encoder-decoder model, by taking in three values for a SMILES sequence: a value vector (V), a query vector (Q) and a key vector (K).
Each vector is similar to a type of word embedding, specifically for determining the compatibility of neighbouring tokens. From these vectors, a dot production attention is derived from the dot product of the query vector of one word, and the key vector of the other.
A scaling factor of $\frac{1}{\sqrt{d_k}}$is added to the dot product attention such that the value doesn't grow too large in respect to $d_k$, the dimension of the key. The softmax normalization function is applied to return a score between 0 to 1 for each individual token:
\begin{equation} \textrm{Attention}(Q, K, V) = \textrm{softmax} \left (\frac{QK^T}{\sqrt{d_k}} \right )V \end{equation}
Visualizing the Attention Mechanism in ChemBERTa using BertViz ¶
BertViz is a tool for visualizing attention in the Transformer model, supporting all models from the transformers library (BERT, GPT-2, XLNet, RoBERTa, XLM, CTRL, etc.). It extends the Tensor2Tensor visualization tool by Llion Jones and the transformers library from HuggingFace.
Using this tool, we can easily plug in ChemBERTa from the HuggingFace model hub and visualize the attention patterns produced by one or more attention heads in a given transformer layer. This is known as the attention-head view.
Lets start by obtaining a Javascript object for d3.js and jquery to create interactive visualizations:
%%javascript
require.config({
paths: {
d3: '//cdnjs.cloudflare.com/ajax/libs/d3/3.4.8/d3.min',
jquery: '//ajax.googleapis.com/ajax/libs/jquery/2.0.0/jquery.min',
}
});
def call_html():
import IPython
display(IPython.core.display.HTML('''
<script src="/static/components/requirejs/require.js"></script>
<script>
requirejs.config({
paths: {
base: '/static/base',
"d3": "https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.8/d3.min",
jquery: '//ajax.googleapis.com/ajax/libs/jquery/2.0.0/jquery.min',
},
});
</script>
'''))
Now, we create an instance of ChemBERTa, tokenize a set of SMILES strings, and compute the attention for each head in the transformer. There are two available models hosted by DeepChem on HuggingFace's model hub, one being
seyonec/ChemBERTa-zinc-base-v1
which is the ChemBERTa model trained via masked lagnuage modelling (MLM) on the ZINC100k dataset, and the other being
seyonec/ChemBERTa-zinc250k-v1
, which is trained via MLM on the larger ZINC250k dataset.
In the following example, we take two SMILES molecules from the ZINC database with nearly identical chemical structure, the only difference being rooted in chiral specification (hence the additional
‘@‘
symbol). This is a feature of molecules which indicates that there exists tetrahedral centres.
‘@'
tells us whether the neighbours of a molecule appear in a counter-clockwise order, whereas
‘@@‘
indicates that the neighbours are ordered in a clockwise direction. The model should ideally refer to similar substructures in each SMILES string with a higher attention weightage.
Lets look at the first SMILES string:
CCCCC[C@@H](Br)CC
:
m = Chem.MolFromSmiles('CCCCC[C@@H](Br)CC')
fig = Draw.MolToMPL(m, size=(200, 200))

And the second SMILES string,
CCCCC[C@H](Br)CC
:
m = Chem.MolFromSmiles('CCCCC[C@H](Br)CC')
fig = Draw.MolToMPL(m, size=(200,200))

The visualization below shows the attention induced by a sample input SMILES. This view visualizes attention as lines connecting the tokens being updated (left) with the tokens being attended to (right), following the design of the figures above. Color intensity reflects the attention weight; weights close to one show as very dark lines, while weights close to zero appear as faint lines or are not visible at all. The user may highlight a particular SMILES character to see the attention from that token only. This visualization is called the attention-head view. It is based on the excellent Tensor2Tensor visualization tool, and are all generated by the Bertviz library.
from transformers import RobertaModel, RobertaTokenizer
from bertviz import head_view
model_version = 'seyonec/PubChem10M_SMILES_BPE_450k'
model = RobertaModel.from_pretrained(model_version, output_attentions=True)
tokenizer = RobertaTokenizer.from_pretrained(model_version)
sentence_a = "CCCCC[C@@H](Br)CC"
sentence_b = "CCCCC[C@H](Br)CC"
inputs = tokenizer.encode_plus(sentence_a, sentence_b, return_tensors='pt', add_special_tokens=True)
input_ids = inputs['input_ids']
attention = model(input_ids)[-1]
input_id_list = input_ids[0].tolist() # Batch index 0
tokens = tokenizer.convert_ids_to_tokens(input_id_list)
call_html()
head_view(attention, tokens)
Smiles-Tokenizer Attention by Head View ¶
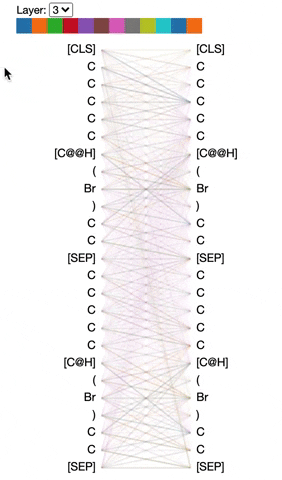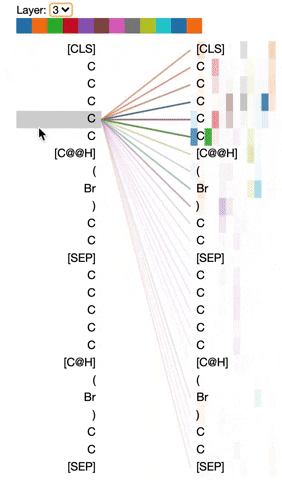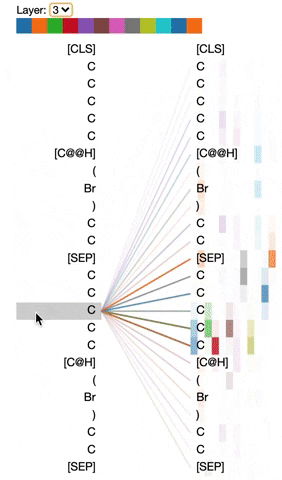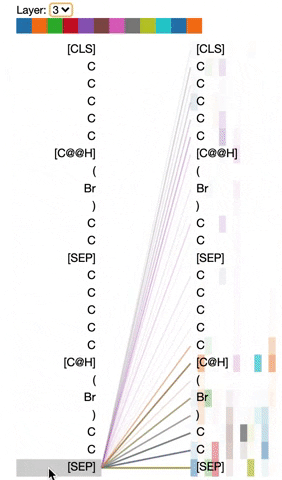
The visualization shows that attention is highest between words that don’t cross a boundary between the two SMILES strings; the model seems to understand that it should relate tokens to other tokens in the same molecule in order to best understand their context.
There are many other fascinating visualizations we can do, such as a neuron-by neuron analysis of attention or a model overview that visualizes all of the heads at once:
Attention by Head View: ¶
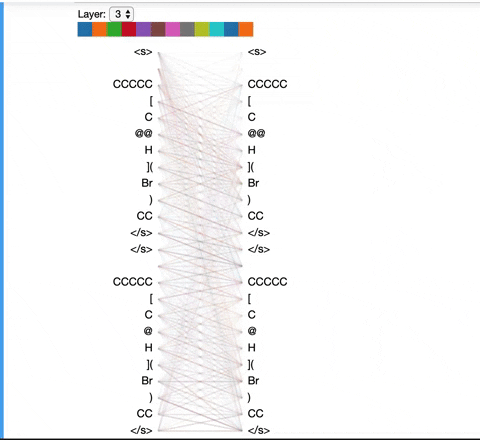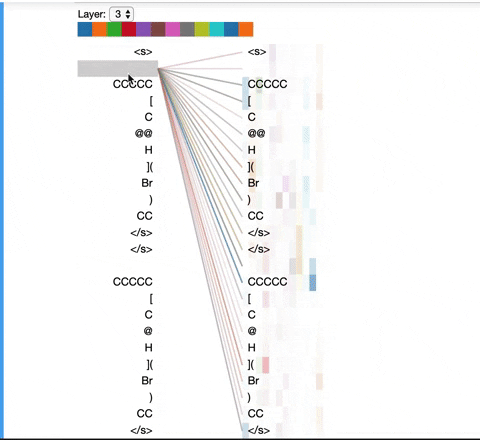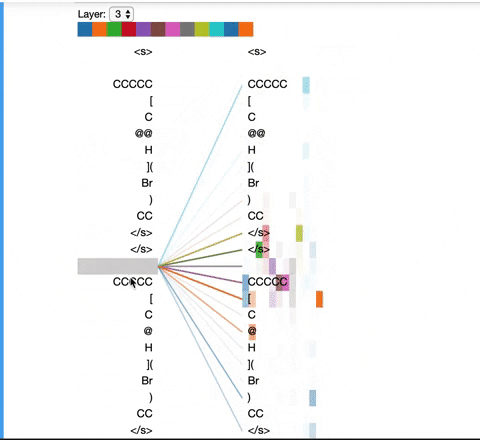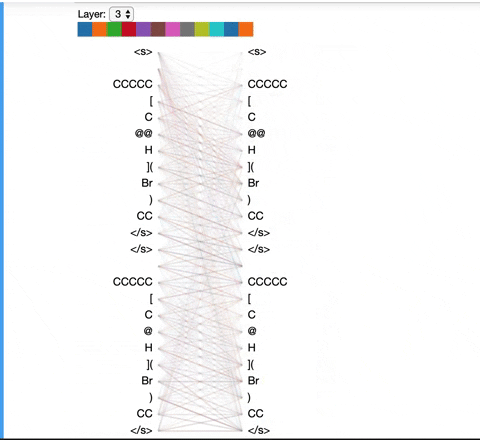
Model View: ¶

Neuron-by-neuron view: ¶

You can try out the ChemBERTa attention visualization demo's in more detail, with custom SMILES/SELFIES strings, tokenizers, and more in the public library, here .
What is Transfer Learning, and how does ChemBERTa utilize it? ¶
Transfer learning is a research problem in machine learning that focuses on storing knowledge gained while solving one problem and applying it to a different but related problem .
By pre-training directly on SMILES strings, and teaching ChemBERTa to recognize masked tokens in each string, the model learns a strong molecular representation. We then can take this model, trained on a structural chemistry task, and apply it to a suite of classification tasks in the MoleculeNet suite, from Tox21 to BBBP!
Fine-tuning ChemBERTa on a Small Mollecular Dataset ¶
Our fine-tuning dataset, ClinTox, consists of qualitative data of drugs approved by the FDA and those that have failed clinical trials for toxicity reasons.
The ClinTox dataset consists of 1478 binary labels for toxicity, using the SMILES representations for identifying molecules. The computational models produced from the dataset could become decision-making tools for government agencies in determining which drugs are of the greatest potential concern to human health. Additionally, these models can act as drug screening tools in the drug discovery pipelines for toxicity.
Let's start by importing the MolNet dataloder from
bert-loves-chemistry
, before importing apex and transformers, the tool which will allow us to import the ChemBERTA language model (LM) trained on PubChem-10M.
%cd /content/bert-loves-chemistry
/content/bert-loves-chemistry
!pwd
/content/bert-loves-chemistry
import os
import numpy as np
import pandas as pd
from typing import List
# import molnet loaders from deepchem
from deepchem.molnet import load_bbbp, load_clearance, load_clintox, load_delaney, load_hiv, load_qm7, load_tox21
from rdkit import Chem
# import MolNet dataloder from bert-loves-chemistry fork
from chemberta.utils.molnet_dataloader import load_molnet_dataset, write_molnet_dataset_for_chemprop
But why use custom Smiles-Tokenizer's over BPE? ¶
In this tutorial, we will be comparing the BPE tokenization algorithm with a custom SmilesTokenizer based on a regex pattern, which we have released as part of DeepChem. To compare tokenizers, we pretrained an identical model tokenized using this novel tokenizer, on the PubChem-1M set. The pretrained model was evaluated on the BBBP and Tox21 in the paper. We found that the SmilesTokenizer narrowly outperformed the BPE algorithm by ∆PRC-AUC = $+0.021$.
Though this result suggests that a more semantically relevant tokenization may provide performance benefits, further benchmarking on additional datasets is needed to validate this finding. In this tutorial, we aim to do so, by testing this alternate model on the ClinTox dataset.
Let's fetch the Smiles Tokenizer's character per line vocabulary file, which can bve loaded from the DeepChem S3 data bucket:
!wget https://deepchemdata.s3-us-west-1.amazonaws.com/datasets/vocab.txt
--2021-03-18 14:48:45-- https://deepchemdata.s3-us-west-1.amazonaws.com/datasets/vocab.txt Resolving deepchemdata.s3-us-west-1.amazonaws.com (deepchemdata.s3-us-west-1.amazonaws.com)... 52.219.113.41 Connecting to deepchemdata.s3-us-west-1.amazonaws.com (deepchemdata.s3-us-west-1.amazonaws.com)|52.219.113.41|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 3524 (3.4K) [text/plain] Saving to: ‘vocab.txt’ vocab.txt 100%[===================>] 3.44K --.-KB/s in 0s 2021-03-18 14:48:46 (62.2 MB/s) - ‘vocab.txt’ saved [3524/3524]
Lets use the MolNet dataloader to generate scaffold splits from the ClinTox dataset.
tasks, (train_df, valid_df, test_df), transformers = load_molnet_dataset("clintox", tasks_wanted=None)
'split' is deprecated. Use 'splitter' instead.
Failed to featurize datapoint 7, None. Appending empty array
Exception message: Python argument types in
rdkit.Chem.rdmolfiles.CanonicalRankAtoms(NoneType)
did not match C++ signature:
CanonicalRankAtoms(RDKit::ROMol mol, bool breakTies=True, bool includeChirality=True, bool includeIsotopes=True)
Failed to featurize datapoint 302, None. Appending empty array
Exception message: Python argument types in
rdkit.Chem.rdmolfiles.CanonicalRankAtoms(NoneType)
did not match C++ signature:
CanonicalRankAtoms(RDKit::ROMol mol, bool breakTies=True, bool includeChirality=True, bool includeIsotopes=True)
Failed to featurize datapoint 983, None. Appending empty array
Exception message: Python argument types in
rdkit.Chem.rdmolfiles.CanonicalRankAtoms(NoneType)
did not match C++ signature:
CanonicalRankAtoms(RDKit::ROMol mol, bool breakTies=True, bool includeChirality=True, bool includeIsotopes=True)
Failed to featurize datapoint 984, None. Appending empty array
Exception message: Python argument types in
rdkit.Chem.rdmolfiles.CanonicalRankAtoms(NoneType)
did not match C++ signature:
CanonicalRankAtoms(RDKit::ROMol mol, bool breakTies=True, bool includeChirality=True, bool includeIsotopes=True)
Failed to featurize datapoint 1219, None. Appending empty array
Exception message: Python argument types in
rdkit.Chem.rdmolfiles.CanonicalRankAtoms(NoneType)
did not match C++ signature:
CanonicalRankAtoms(RDKit::ROMol mol, bool breakTies=True, bool includeChirality=True, bool includeIsotopes=True)
Failed to featurize datapoint 1220, None. Appending empty array
Exception message: Python argument types in
rdkit.Chem.rdmolfiles.CanonicalRankAtoms(NoneType)
did not match C++ signature:
CanonicalRankAtoms(RDKit::ROMol mol, bool breakTies=True, bool includeChirality=True, bool includeIsotopes=True)
/usr/local/lib/python3.7/dist-packages/numpy/core/_asarray.py:83: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return array(a, dtype, copy=False, order=order)
Using tasks ['CT_TOX'] from available tasks for clintox: ['FDA_APPROVED', 'CT_TOX']
If you're only running the toxicity prediction portion of this tutorial, make sure you install transformers here. If you've ran all the cells before, you can ignore this install as we've already done
pip install transformers
before.
!pip install transformers
Requirement already satisfied: transformers in /usr/local/lib/python3.7/dist-packages (4.4.1) Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.7/dist-packages (from transformers) (4.59.0) Requirement already satisfied: importlib-metadata; python_version < "3.8" in /usr/local/lib/python3.7/dist-packages (from transformers) (3.7.2) Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.7/dist-packages (from transformers) (2019.12.20) Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.7/dist-packages (from transformers) (1.19.5) Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from transformers) (2.23.0) Requirement already satisfied: tokenizers<0.11,>=0.10.1 in /usr/local/lib/python3.7/dist-packages (from transformers) (0.10.1) Requirement already satisfied: sacremoses in /usr/local/lib/python3.7/dist-packages (from transformers) (0.0.43) Requirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from transformers) (3.0.12) Requirement already satisfied: packaging in /usr/local/lib/python3.7/dist-packages (from transformers) (20.9) Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata; python_version < "3.8"->transformers) (3.4.1) Requirement already satisfied: typing-extensions>=3.6.4; python_version < "3.8" in /usr/local/lib/python3.7/dist-packages (from importlib-metadata; python_version < "3.8"->transformers) (3.7.4.3) Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (3.0.4) Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (2.10) Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (1.24.3) Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (2020.12.5) Requirement already satisfied: click in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers) (7.1.2) Requirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers) (1.15.0) Requirement already satisfied: joblib in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers) (1.0.1) Requirement already satisfied: pyparsing>=2.0.2 in /usr/local/lib/python3.7/dist-packages (from packaging->transformers) (2.4.7)
train_df
| text | labels | |
|---|---|---|
| 0 | CC(C)C[C@H](NC(=O)CNC(=O)c1cc(Cl)ccc1Cl)B(O)O | 0 |
| 1 | O=C(NCC(O)CO)c1c(I)c(C(=O)NCC(O)CO)c(I)c(N(CCO... | 1 |
| 2 | Clc1cc(Cl)c(OCC#CI)cc1Cl | 1 |
| 3 | N#Cc1cc(NC(=O)C(=O)[O-])c(Cl)c(NC(=O)C(=O)[O-])c1 | 1 |
| 4 | NS(=O)(=O)c1cc(Cl)c(Cl)c(S(N)(=O)=O)c1 | 1 |
| ... | ... | ... |
| 1177 | CC(C[NH2+]C1CCCCC1)OC(=O)c1ccccc1 | 1 |
| 1178 | CC(C(=O)[O-])c1ccc(C(=O)c2cccs2)cc1 | 1 |
| 1179 | CC(c1cc2ccccc2s1)N(O)C(N)=O | 1 |
| 1180 | CC(O)C(CO)NC(=O)C1CSSCC(NC(=O)C([NH3+])Cc2cccc... | 1 |
| 1181 | CC(C)OC(=O)CCC/C=C\C[C@H]1[C@@H](O)C[C@@H](O)[... | 1 |
1182 rows × 2 columns
valid_df
| text | labels | |
|---|---|---|
| 0 | CC(C)OC(=O)CCC/C=C\C[C@H]1[C@@H](O)C[C@@H](O)[... | 1 |
| 1 | CC(C)Nc1cccnc1N1CCN(C(=O)c2cc3cc(NS(C)(=O)=O)c... | 1 |
| 2 | CC(C)n1c(/C=C/[C@H](O)C[C@H](O)CC(=O)[O-])c(-c... | 1 |
| 3 | CC(C)COCC(CN(Cc1ccccc1)c1ccccc1)[NH+]1CCCC1 | 1 |
| 4 | CSCC[C@H](NC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)... | 1 |
| ... | ... | ... |
| 143 | C[C@H](OC(=O)c1ccccc1)C1=CCC23OCC[NH+](C)CC12C... | 1 |
| 144 | C[C@@H](c1ncncc1F)[C@](O)(Cn1cncn1)c1ccc(F)cc1F | 1 |
| 145 | CC(C)C[C@@H](NC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]... | 1 |
| 146 | C[C@H](O)[C@H](O)[C@H]1CNc2[nH]c(N)nc(=O)c2N1 | 1 |
| 147 | C[NH+]1C[C@H](C(=O)N[C@]2(C)O[C@@]3(O)[C@@H]4C... | 1 |
148 rows × 2 columns
test_df
| text | labels | |
|---|---|---|
| 0 | C[NH+]1C[C@H](C(=O)N[C@]2(C)O[C@@]3(O)[C@@H]4C... | 1 |
| 1 | C[C@]1(Cn2ccnn2)[C@H](C(=O)[O-])N2C(=O)C[C@H]2... | 1 |
| 2 | C[NH+]1CCC[C@@H]1CCO[C@](C)(c1ccccc1)c1ccc(Cl)cc1 | 1 |
| 3 | Nc1nc(NC2CC2)c2ncn([C@H]3C=C[C@@H](CO)C3)c2n1 | 1 |
| 4 | OC[C@H]1O[C@@H](n2cnc3c2NC=[NH+]C[C@H]3O)C[C@@... | 1 |
| ... | ... | ... |
| 143 | O=C1O[C@H]([C@@H](O)CO)C([O-])=C1O | 1 |
| 144 | C#CCC(Cc1cnc2nc(N)nc(N)c2n1)c1ccc(C(=O)N[C@@H]... | 1 |
| 145 | C#CC[NH2+][C@@H]1CCc2ccccc21 | 1 |
| 146 | [H]/[NH+]=C(\N)c1ccc(OCCCCCOc2ccc(/C(N)=[NH+]/... | 1 |
| 147 | [H]/[NH+]=C(\N)C1=CC(=O)/C(=C\C=c2ccc(=C(N)[NH... | 1 |
148 rows × 2 columns
From here, lets set up a logger to record if any issues occur, and notify us if there are any problems with the arguments we've set for the model.
from simpletransformers.classification import ClassificationModel
import logging
logging.basicConfig(level=logging.INFO)
transformers_logger = logging.getLogger("transformers")
transformers_logger.setLevel(logging.WARNING)
Now, using
simple-transformer
, let's load the pre-trained model from HuggingFace's useful model-hub. We'll set the number of epochs to 10 in the arguments, but you can train for longer, and pass early-stopping as an argument to prevent overfitting. Also make sure that
auto_weights
is set to True to do automatic weight balancing, as we are dealing with imbalanced toxicity datasets.
from simpletransformers.classification import ClassificationModel, ClassificationArgs
model = ClassificationModel('roberta', 'seyonec/PubChem10M_SMILES_BPE_396_250', args={'evaluate_each_epoch': True, 'evaluate_during_training_verbose': True, 'no_save': True, 'num_train_epochs': 10, 'auto_weights': True}) # You can set class weights by using the optional weight argument
INFO:filelock:Lock 139908324261648 acquired on /root/.cache/huggingface/transformers/fac1cb3c26e15ed0ea455cf81115189edfd28b0cfa0ad7dca9922b8319475530.6662bce220e70bb69e1cc10c236b68e778001c010a6880b624c2159a235be52d.lock
Downloading: 0%| | 0.00/515 [00:00<?, ?B/s]
INFO:filelock:Lock 139908324261648 released on /root/.cache/huggingface/transformers/fac1cb3c26e15ed0ea455cf81115189edfd28b0cfa0ad7dca9922b8319475530.6662bce220e70bb69e1cc10c236b68e778001c010a6880b624c2159a235be52d.lock INFO:filelock:Lock 139908246375248 acquired on /root/.cache/huggingface/transformers/fca63b78d86d5e1ceec66e1d9f3ff8ec0d078055e0ba387926cf9baf6b86ce79.93843c462ba2f6d2fecf01338be4b448f0b6f8f7dfed6535b7ffbd3e4203f223.lock
Downloading: 0%| | 0.00/336M [00:00<?, ?B/s]
INFO:filelock:Lock 139908246375248 released on /root/.cache/huggingface/transformers/fca63b78d86d5e1ceec66e1d9f3ff8ec0d078055e0ba387926cf9baf6b86ce79.93843c462ba2f6d2fecf01338be4b448f0b6f8f7dfed6535b7ffbd3e4203f223.lock Some weights of the model checkpoint at seyonec/PubChem10M_SMILES_BPE_396_250 were not used when initializing RobertaForSequenceClassification: ['lm_head.bias', 'lm_head.dense.weight', 'lm_head.dense.bias', 'lm_head.layer_norm.weight', 'lm_head.layer_norm.bias', 'lm_head.decoder.weight', 'lm_head.decoder.bias'] - This IS expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model). - This IS NOT expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model). Some weights of RobertaForSequenceClassification were not initialized from the model checkpoint at seyonec/PubChem10M_SMILES_BPE_396_250 and are newly initialized: ['classifier.dense.weight', 'classifier.dense.bias', 'classifier.out_proj.weight', 'classifier.out_proj.bias'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference. INFO:filelock:Lock 139908246200848 acquired on /root/.cache/huggingface/transformers/3df58ba3fcca472da48db1fb3a669ebed9808cae886e8f7b99e6aed197a808cb.98d8cf992f31bc68994648ce3120c3cb14bf75e4e60a70a06cc61cce44b902f0.lock
Downloading: 0%| | 0.00/165k [00:00<?, ?B/s]
INFO:filelock:Lock 139908246200848 released on /root/.cache/huggingface/transformers/3df58ba3fcca472da48db1fb3a669ebed9808cae886e8f7b99e6aed197a808cb.98d8cf992f31bc68994648ce3120c3cb14bf75e4e60a70a06cc61cce44b902f0.lock INFO:filelock:Lock 139908246331344 acquired on /root/.cache/huggingface/transformers/3aa7993e4d850d3abfc9b05959c762d864591d3d5d450310e9ccb1ef0b2c339c.07b622242dcc6c7fd6a5f356d2e200c4f44be0279b767b85afcb24e778809d3c.lock
Downloading: 0%| | 0.00/101k [00:00<?, ?B/s]
INFO:filelock:Lock 139908246331344 released on /root/.cache/huggingface/transformers/3aa7993e4d850d3abfc9b05959c762d864591d3d5d450310e9ccb1ef0b2c339c.07b622242dcc6c7fd6a5f356d2e200c4f44be0279b767b85afcb24e778809d3c.lock INFO:filelock:Lock 139908246331344 acquired on /root/.cache/huggingface/transformers/4b86306d6b8b22c548d737ae24268401236ad7a42564ddb028bf193f485c55f2.cb2244924ab24d706b02fd7fcedaea4531566537687a539ebb94db511fd122a0.lock
Downloading: 0%| | 0.00/772 [00:00<?, ?B/s]
INFO:filelock:Lock 139908246331344 released on /root/.cache/huggingface/transformers/4b86306d6b8b22c548d737ae24268401236ad7a42564ddb028bf193f485c55f2.cb2244924ab24d706b02fd7fcedaea4531566537687a539ebb94db511fd122a0.lock INFO:filelock:Lock 139908112777168 acquired on /root/.cache/huggingface/transformers/10b820db140011d86e29dad69ed31c58db810e5f85a13982ec9457a63da1bb17.1788df22ba1a6817edb607a56efa931ee13ebad3b3500e58029a8f4e6d799a29.lock
Downloading: 0%| | 0.00/62.0 [00:00<?, ?B/s]
INFO:filelock:Lock 139908112777168 released on /root/.cache/huggingface/transformers/10b820db140011d86e29dad69ed31c58db810e5f85a13982ec9457a63da1bb17.1788df22ba1a6817edb607a56efa931ee13ebad3b3500e58029a8f4e6d799a29.lock
print(model.tokenizer)
PreTrainedTokenizer(name_or_path='seyonec/PubChem10M_SMILES_BPE_396_250', vocab_size=7924, model_max_len=1000000000000000019884624838656, is_fast=False, padding_side='right', special_tokens={'bos_token': AddedToken("<s>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'eos_token': AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'unk_token': AddedToken("<unk>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'sep_token': AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'pad_token': AddedToken("<pad>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'cls_token': AddedToken("<s>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'mask_token': AddedToken("<mask>", rstrip=False, lstrip=True, single_word=False, normalized=True)})
# check if our train and evaluation dataframes are setup properly. There should only be two columns for the SMILES string and its corresponding label.
print("Train Dataset: {}".format(train_df.shape))
print("Eval Dataset: {}".format(valid_df.shape))
print("TEST Dataset: {}".format(test_df.shape))
Train Dataset: (1182, 2) Eval Dataset: (148, 2) TEST Dataset: (148, 2)
Now that we've set everything up, lets get to the fun part: training the model! We use Weights and Biases, which is optional (simply remove
wandb_project
from the list of
args
). Its a really useful tool for monitering the model's training results (such as accuracy, learning rate and loss), alongside custom visualizations of attention and gradients.
When you run this cell, Weights and Biases will ask for an account, which you can setup through a Github account, giving you an authorization API key which you can paste into the output of the cell. Again, this is completely optional and it can be removed from the list of arguments.
!wandb login
wandb: You can find your API key in your browser here: https://wandb.ai/authorize wandb: Paste an API key from your profile and hit enter: wandb: Appending key for api.wandb.ai to your netrc file: /root/.netrc
Finally, the moment we've been waiting for! Let's train the model on the train scaffold set of ClinTox, and monitor our runs using W&B. We will evaluate the performance of our model each epoch using the validation set.
# Create directory to store model weights (change path accordingly to where you want!)
!mkdir BPE_PubChem_10M_ClinTox_run
# Train the model
model.train_model(train_df, eval_df=valid_df, output_dir='/content/BPE_PubChem_10M_ClinTox_run', args={'wandb_project': 'project-name'})
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
0%| | 0/2 [00:00<?, ?it/s]
INFO:simpletransformers.classification.classification_utils: Saving features into cached file cache_dir/cached_train_roberta_128_2_1182
Epoch: 0%| | 0/10 [00:00<?, ?it/s]
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training. wandb: Currently logged in as: seyonec (use `wandb login --relogin` to force relogin)
Syncing run snowy-firefly-250 to Weights & Biases (Documentation) .
Project page: https://wandb.ai/seyonec/project-name
Run page: https://wandb.ai/seyonec/project-name/runs/1t7dyfs4
Run data is saved locally in
/content/bert-loves-chemistry/wandb/run-20210318_145336-1t7dyfs4
Running Epoch 0 of 10: 0%| | 0/148 [00:00<?, ?it/s]
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py:760: UserWarning: Using non-full backward hooks on a Module that does not return a single Tensor or a tuple of Tensors is deprecated and will be removed in future versions. This hook will be missing some of the grad_output. Please use register_full_backward_hook to get the documented behavior.
warnings.warn("Using non-full backward hooks on a Module that does not return a "
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py:795: UserWarning: Using a non-full backward hook when the forward contains multiple autograd Nodes is deprecated and will be removed in future versions. This hook will be missing some grad_input. Please use register_full_backward_hook to get the documented behavior.
warnings.warn("Using a non-full backward hook when the forward contains multiple autograd Nodes "
Running Epoch 1 of 10: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 2 of 10: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 3 of 10: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 4 of 10: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 5 of 10: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 6 of 10: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 7 of 10: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 8 of 10: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 9 of 10: 0%| | 0/148 [00:00<?, ?it/s]
INFO:simpletransformers.classification.classification_model: Training of roberta model complete. Saved to /content/BPE_PubChem_10M_ClinTox_run.
(1480, 0.10153530814545406)
Let's install scikit-learn now, to evaluate the model we've trained. We will be using the accuracy and PRC-AUC metrics (average precision score).
import sklearn
# accuracy
result, model_outputs, wrong_predictions = model.eval_model(test_df, acc=sklearn.metrics.accuracy_score)
# ROC-PRC
result, model_outputs, wrong_predictions = model.eval_model(test_df, acc=sklearn.metrics.average_precision_score)
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used. INFO:simpletransformers.classification.classification_utils: Saving features into cached file cache_dir/cached_dev_roberta_128_2_148
Running Evaluation: 0%| | 0/19 [00:00<?, ?it/s]
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
Waiting for W&B process to finish, PID 4627
Program ended successfully.
VBox(children=(Label(value=' 0.01MB of 0.01MB uploaded (0.00MB deduped)\r'), FloatProgress(value=1.0, max=1.0)…
/content/bert-loves-chemistry/wandb/run-20210318_145336-1t7dyfs4/logs/debug.log
/content/bert-loves-chemistry/wandb/run-20210318_145336-1t7dyfs4/logs/debug-internal.log
Run summary:
| Training loss | 0.0003 |
| lr | 0.0 |
| global_step | 1450 |
| _runtime | 116 |
| _timestamp | 1616079332 |
| _step | 28 |
Run history:
| Training loss | █▁▁▁▂█▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁ |
| lr | ▅██▇▇▇▇▆▆▆▆▅▅▅▅▄▄▄▄▃▃▃▃▂▂▂▂▁▁ |
| global_step | ▁▁▁▂▂▂▃▃▃▃▃▄▄▄▅▅▅▅▅▆▆▆▇▇▇▇▇██ |
| _runtime | ▁▁▂▂▂▂▂▃▃▃▄▄▄▄▄▅▅▅▅▆▆▆▇▇▇▇▇██ |
| _timestamp | ▁▁▂▂▂▂▂▃▃▃▄▄▄▄▄▅▅▅▅▆▆▆▇▇▇▇▇██ |
| _step | ▁▁▁▂▂▂▃▃▃▃▃▄▄▄▅▅▅▅▅▆▆▆▇▇▇▇▇██ |
Syncing run summer-pyramid-251 to Weights & Biases (Documentation) .
Project page: https://wandb.ai/seyonec/project-name
Run page: https://wandb.ai/seyonec/project-name/runs/a6brkv9i
Run data is saved locally in
/content/bert-loves-chemistry/wandb/run-20210318_145535-a6brkv9i
INFO:simpletransformers.classification.classification_model:{'mcc': 0.664470436990577, 'tp': 138, 'tn': 5, 'fp': 4, 'fn': 1, 'auroc': 0.8281374900079936, 'auprc': 0.9855371861072479, 'acc': 0.9662162162162162, 'eval_loss': 0.2469284737426757}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file cache_dir/cached_dev_roberta_128_2_148
Running Evaluation: 0%| | 0/19 [00:00<?, ?it/s]
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
Waiting for W&B process to finish, PID 4677
Program ended successfully.
VBox(children=(Label(value=' 0.00MB of 0.00MB uploaded (0.00MB deduped)\r'), FloatProgress(value=1.0, max=1.0)…
/content/bert-loves-chemistry/wandb/run-20210318_145535-a6brkv9i/logs/debug.log
/content/bert-loves-chemistry/wandb/run-20210318_145535-a6brkv9i/logs/debug-internal.log
Run summary:
| _runtime | 3 |
| _timestamp | 1616079341 |
| _step | 2 |
Run history:
| _runtime | ▁▁▁ |
| _timestamp | ▁▁▁ |
| _step | ▁▅█ |
Syncing run vivid-morning-252 to Weights & Biases (Documentation) .
Project page: https://wandb.ai/seyonec/project-name
Run page: https://wandb.ai/seyonec/project-name/runs/7bl6wyef
Run data is saved locally in
/content/bert-loves-chemistry/wandb/run-20210318_145541-7bl6wyef
INFO:simpletransformers.classification.classification_model:{'mcc': 0.664470436990577, 'tp': 138, 'tn': 5, 'fp': 4, 'fn': 1, 'auroc': 0.8281374900079936, 'auprc': 0.9855371861072479, 'acc': 0.9715961528455196, 'eval_loss': 0.2469284737426757}
The model performs pretty well, averaging above 97% ROC-PRC after training on only ~1400 data samples and 150 positive leads in a couple of minutes! We can clearly see the predictive power of transfer learning, and approaches like these are becoming increasing popular in the pharmaceutical industry where larger datasets are scarce. By training on more epochs and tasks, we can probably boost the accuracy as well!
Lets evaluate the model on one last string from ClinTox's test set for toxicity. The model should predict 1, meaning the drug failed clinical trials for toxicity reasons and wasn't approved by the FDA.
# Lets input a molecule with a toxicity value of 1
predictions, raw_outputs = model.predict(['C1=C(C(=O)NC(=O)N1)F'])
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used. INFO:simpletransformers.classification.classification_utils: Saving features into cached file cache_dir/cached_dev_roberta_128_2_1
0%| | 0/1 [00:00<?, ?it/s]
print(predictions)
print(raw_outputs)
[1] [[-4.51171875 4.58203125]]
The model predicts the sample correctly! Some future tasks may include using the same model on multiple tasks (Tox21 provides multiple tasks relating to different biochemical pathways for toxicity, as an example), through multi-task classification, as well as training on a larger dataset such as HIV, one of the other harder tasks in molecular machine learning. This will be expanded on in future work!
Benchmarking Smiles-Tokenizer ChemBERTa models on ClinTox ¶
Now lets compare how this model performs to a similar variant of ChemBERTa, that utilizes a different tokenizer, the SmilesTokenizer which is built-in to DeepChem! Let see if using a tokenizer which splits SMILES sequences into syntatically relevant chemical tokens performs differently, especially on molecular property prediction.
First off, lets initialize this variant model:
from simpletransformers.classification import ClassificationModel, ClassificationArgs
model = ClassificationModel('roberta', 'seyonec/SMILES_tokenized_PubChem_shard00_160k', args={'evaluate_each_epoch': True, 'evaluate_during_training_verbose': True, 'no_save': True, 'num_train_epochs': 15, 'auto_weights': True}) # You can set class weights by using the optional weight argument
INFO:filelock:Lock 139908321724944 acquired on /root/.cache/huggingface/transformers/30ac96f427325ec13c51dfd4507636207bdb9be77521b77ad334279cf1f5c184.f6ebc79ab803ca349ef7b469b0fbe6aa40d053e3c1c2da0501521c46c2a51bb7.lock
Downloading: 0%| | 0.00/515 [00:00<?, ?B/s]
INFO:filelock:Lock 139908321724944 released on /root/.cache/huggingface/transformers/30ac96f427325ec13c51dfd4507636207bdb9be77521b77ad334279cf1f5c184.f6ebc79ab803ca349ef7b469b0fbe6aa40d053e3c1c2da0501521c46c2a51bb7.lock INFO:filelock:Lock 139908321724944 acquired on /root/.cache/huggingface/transformers/3a95725b53b9958c41159cd19bbde8dad8e5988ff0a6971189ef3b6b625e5f5b.ae1cdbb61878f3444ee2c5aa28dfc4577a642a31729bf0b477ccd4d948ad9081.lock
Downloading: 0%| | 0.00/336M [00:00<?, ?B/s]
INFO:filelock:Lock 139908321724944 released on /root/.cache/huggingface/transformers/3a95725b53b9958c41159cd19bbde8dad8e5988ff0a6971189ef3b6b625e5f5b.ae1cdbb61878f3444ee2c5aa28dfc4577a642a31729bf0b477ccd4d948ad9081.lock Some weights of the model checkpoint at seyonec/SMILES_tokenized_PubChem_shard00_160k were not used when initializing RobertaForSequenceClassification: ['lm_head.bias', 'lm_head.dense.weight', 'lm_head.dense.bias', 'lm_head.layer_norm.weight', 'lm_head.layer_norm.bias', 'lm_head.decoder.weight', 'lm_head.decoder.bias'] - This IS expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model). - This IS NOT expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model). Some weights of RobertaForSequenceClassification were not initialized from the model checkpoint at seyonec/SMILES_tokenized_PubChem_shard00_160k and are newly initialized: ['classifier.dense.weight', 'classifier.dense.bias', 'classifier.out_proj.weight', 'classifier.out_proj.bias'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference. INFO:filelock:Lock 139906415180368 acquired on /root/.cache/huggingface/transformers/b5b8a0f3afd321810f8ab3864fd3b562ac78b45cffd986e1fe33b0dae85e4149.dcb6a95ce7ba1c00e125887fcabb2ed5074718e901096d78d86a6d720f57db60.lock
Downloading: 0%| | 0.00/8.14k [00:00<?, ?B/s]
INFO:filelock:Lock 139906415180368 released on /root/.cache/huggingface/transformers/b5b8a0f3afd321810f8ab3864fd3b562ac78b45cffd986e1fe33b0dae85e4149.dcb6a95ce7ba1c00e125887fcabb2ed5074718e901096d78d86a6d720f57db60.lock INFO:filelock:Lock 139908023274512 acquired on /root/.cache/huggingface/transformers/e994bb60d8301b04451980e779af11e3fd55dfc1a97545f7ed9f25c4bb0144f8.0d2bc617dafe1551d37a1ee810476c86b8fcb92acede8e1ee6faf97e76000351.lock
Downloading: 0.00B [00:00, ?B/s]
INFO:filelock:Lock 139908023274512 released on /root/.cache/huggingface/transformers/e994bb60d8301b04451980e779af11e3fd55dfc1a97545f7ed9f25c4bb0144f8.0d2bc617dafe1551d37a1ee810476c86b8fcb92acede8e1ee6faf97e76000351.lock INFO:filelock:Lock 139906414851088 acquired on /root/.cache/huggingface/transformers/186e51d9d044b8d234c30b286f58a87c44409db18948a3fd9b40fa795a4b89ad.dd8bd9bfd3664b530ea4e645105f557769387b3da9f79bdb55ed556bdd80611d.lock
Downloading: 0%| | 0.00/112 [00:00<?, ?B/s]
INFO:filelock:Lock 139906414851088 released on /root/.cache/huggingface/transformers/186e51d9d044b8d234c30b286f58a87c44409db18948a3fd9b40fa795a4b89ad.dd8bd9bfd3664b530ea4e645105f557769387b3da9f79bdb55ed556bdd80611d.lock INFO:filelock:Lock 139906414851152 acquired on /root/.cache/huggingface/transformers/c9175af31705aea512d539a7e6d96803af809ba0d307eb762cb4b6a1c1af5ced.444225800184b0dbd3b86bfd798c4195c0af90f2b3b1540552cacd505c3f7c60.lock
Downloading: 0%| | 0.00/327 [00:00<?, ?B/s]
INFO:filelock:Lock 139906414851152 released on /root/.cache/huggingface/transformers/c9175af31705aea512d539a7e6d96803af809ba0d307eb762cb4b6a1c1af5ced.444225800184b0dbd3b86bfd798c4195c0af90f2b3b1540552cacd505c3f7c60.lock Special tokens have been added in the vocabulary, make sure the associated word embedding are fine-tuned or trained.
print(model.tokenizer)
PreTrainedTokenizer(name_or_path='seyonec/SMILES_tokenized_PubChem_shard00_160k', vocab_size=591, model_max_len=514, is_fast=False, padding_side='right', special_tokens={'bos_token': AddedToken("<s>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'eos_token': AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'})
# check if our train and evaluation dataframes are setup properly. There should only be two columns for the SMILES string and its corresponding label.
print("Train Dataset: {}".format(train_df.shape))
print("Eval Dataset: {}".format(valid_df.shape))
print("TEST Dataset: {}".format(test_df.shape))
Train Dataset: (1182, 2) Eval Dataset: (148, 2) TEST Dataset: (148, 2)
Now that we've set everything up, lets get to the fun part: training the model! We use Weights and Biases, which is optional (simply remove
wandb_project
from the list of
args
). Its a really useful tool for monitering the model's training results (such as accuracy, learning rate and loss), alongside custom visualizations of attention and gradients.
When you run this cell, Weights and Biases will ask for an account, which you can setup through a Github account, giving you an authorization API key which you can paste into the output of the cell. Again, this is completely optional and it can be removed from the list of arguments.
!wandb login
wandb: Currently logged in as: seyonec (use `wandb login --relogin` to force relogin)
# Create directory to store model weights (change path accordingly to where you want!)
!mkdir SmilesTokenizer_PubChem_10M_ClinTox_run
# Train the model
model.train_model(train_df, eval_df=valid_df, output_dir='/content/SmilesTokenizer_PubChem_10M_ClinTox_run', args={'wandb_project': 'project-name'})
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
0%| | 0/2 [00:00<?, ?it/s]
INFO:simpletransformers.classification.classification_utils: Saving features into cached file cache_dir/cached_train_roberta_128_2_1182
Epoch: 0%| | 0/15 [00:00<?, ?it/s]
INFO:simpletransformers.classification.classification_model: Initializing WandB run for training.
Waiting for W&B process to finish, PID 4711
Program ended successfully.
VBox(children=(Label(value=' 0.00MB of 0.00MB uploaded (0.00MB deduped)\r'), FloatProgress(value=1.0, max=1.0)…
/content/bert-loves-chemistry/wandb/run-20210318_145541-7bl6wyef/logs/debug.log
/content/bert-loves-chemistry/wandb/run-20210318_145541-7bl6wyef/logs/debug-internal.log
Run summary:
| _runtime | 3 |
| _timestamp | 1616079348 |
| _step | 2 |
Run history:
| _runtime | ▁██ |
| _timestamp | ▁██ |
| _step | ▁▅█ |
Syncing run revived-armadillo-253 to Weights & Biases (Documentation) .
Project page: https://wandb.ai/seyonec/project-name
Run page: https://wandb.ai/seyonec/project-name/runs/v04qi4gi
Run data is saved locally in
/content/bert-loves-chemistry/wandb/run-20210318_145608-v04qi4gi
Running Epoch 0 of 15: 0%| | 0/148 [00:00<?, ?it/s]
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py:760: UserWarning: Using non-full backward hooks on a Module that does not return a single Tensor or a tuple of Tensors is deprecated and will be removed in future versions. This hook will be missing some of the grad_output. Please use register_full_backward_hook to get the documented behavior.
warnings.warn("Using non-full backward hooks on a Module that does not return a "
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py:795: UserWarning: Using a non-full backward hook when the forward contains multiple autograd Nodes is deprecated and will be removed in future versions. This hook will be missing some grad_input. Please use register_full_backward_hook to get the documented behavior.
warnings.warn("Using a non-full backward hook when the forward contains multiple autograd Nodes "
Running Epoch 1 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 2 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 3 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 4 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 5 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 6 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 7 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 8 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 9 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 10 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 11 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 12 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 13 of 15: 0%| | 0/148 [00:00<?, ?it/s]
Running Epoch 14 of 15: 0%| | 0/148 [00:00<?, ?it/s]
INFO:simpletransformers.classification.classification_model: Training of roberta model complete. Saved to /content/SmilesTokenizer_PubChem_10M_ClinTox_run.
(2220, 0.09892498987772685)
Let's install scikit-learn now, to evaluate the model we've trained. We will be using the accuracy and PRC-AUC metrics (average precision score).
import sklearn
# accuracy
result, model_outputs, wrong_predictions = model.eval_model(test_df, acc=sklearn.metrics.accuracy_score)
# ROC-PRC
result, model_outputs, wrong_predictions = model.eval_model(test_df, acc=sklearn.metrics.average_precision_score)
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used. INFO:simpletransformers.classification.classification_utils: Saving features into cached file cache_dir/cached_dev_roberta_128_2_148
Running Evaluation: 0%| | 0/19 [00:00<?, ?it/s]
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
Waiting for W&B process to finish, PID 4767
Program ended successfully.
VBox(children=(Label(value=' 0.01MB of 0.01MB uploaded (0.00MB deduped)\r'), FloatProgress(value=1.0, max=1.0)…
/content/bert-loves-chemistry/wandb/run-20210318_145608-v04qi4gi/logs/debug.log
/content/bert-loves-chemistry/wandb/run-20210318_145608-v04qi4gi/logs/debug-internal.log
Run summary:
| Training loss | 0.11875 |
| lr | 0.0 |
| global_step | 2200 |
| _runtime | 175 |
| _timestamp | 1616079546 |
| _step | 43 |
Run history:
| Training loss | ▇▅█▁▁▄▅▆▁▁▁▁▁▁▄▃▁▁▁▁▁▁▄▁▁▁▁▁▁▃▁▁▁▁▂▁▁▃▁▂ |
| lr | ▄▆███▇▇▇▇▇▆▆▆▆▆▆▅▅▅▅▅▄▄▄▄▄▄▃▃▃▃▃▂▂▂▂▂▂▁▁ |
| global_step | ▁▁▁▁▂▂▂▂▂▂▃▃▃▃▃▄▄▄▄▄▅▅▅▅▅▅▆▆▆▆▆▇▇▇▇▇▇███ |
| _runtime | ▁▁▁▁▂▂▂▂▂▂▃▃▃▃▃▄▄▄▄▄▅▅▅▅▅▅▆▆▆▆▆▇▇▇▇▇▇▇██ |
| _timestamp | ▁▁▁▁▂▂▂▂▂▂▃▃▃▃▃▄▄▄▄▄▅▅▅▅▅▅▆▆▆▆▆▇▇▇▇▇▇▇██ |
| _step | ▁▁▁▁▂▂▂▂▂▂▃▃▃▃▃▄▄▄▄▄▅▅▅▅▅▅▆▆▆▆▆▇▇▇▇▇▇███ |
Syncing run pleasant-wave-254 to Weights & Biases (Documentation) .
Project page: https://wandb.ai/seyonec/project-name
Run page: https://wandb.ai/seyonec/project-name/runs/3ti3lfl8
Run data is saved locally in
/content/bert-loves-chemistry/wandb/run-20210318_145908-3ti3lfl8
INFO:simpletransformers.classification.classification_model:{'mcc': 0.3646523331752495, 'tp': 138, 'tn': 2, 'fp': 7, 'fn': 1, 'auroc': 0.8073541167066347, 'auprc': 0.984400271563181, 'acc': 0.9459459459459459, 'eval_loss': 0.3173560830033047}
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used.
INFO:simpletransformers.classification.classification_utils: Saving features into cached file cache_dir/cached_dev_roberta_128_2_148
Running Evaluation: 0%| | 0/19 [00:00<?, ?it/s]
INFO:simpletransformers.classification.classification_model: Initializing WandB run for evaluation.
Waiting for W&B process to finish, PID 4826
Program ended successfully.
VBox(children=(Label(value=' 0.00MB of 0.00MB uploaded (0.00MB deduped)\r'), FloatProgress(value=0.76956648239…
/content/bert-loves-chemistry/wandb/run-20210318_145908-3ti3lfl8/logs/debug.log
/content/bert-loves-chemistry/wandb/run-20210318_145908-3ti3lfl8/logs/debug-internal.log
Run summary:
| _runtime | 3 |
| _timestamp | 1616079554 |
| _step | 2 |
Run history:
| _runtime | ▁▁▁ |
| _timestamp | ▁▁▁ |
| _step | ▁▅█ |
Syncing run dulcet-shadow-255 to Weights & Biases (Documentation) .
Project page: https://wandb.ai/seyonec/project-name
Run page: https://wandb.ai/seyonec/project-name/runs/17769dhr
Run data is saved locally in
/content/bert-loves-chemistry/wandb/run-20210318_145914-17769dhr
INFO:simpletransformers.classification.classification_model:{'mcc': 0.3646523331752495, 'tp': 138, 'tn': 2, 'fp': 7, 'fn': 1, 'auroc': 0.8073541167066347, 'auprc': 0.984400271563181, 'acc': 0.951633958443683, 'eval_loss': 0.3173560830033047}
The model performs incredibly well, averaging above 96% PRC-AUC after training on only ~1400 data samples and 150 positive leads in a couple of minutes! This model was also trained on 1/10th the amount of pre-training data as the PubChem-10M BPE model we used previously, but it still showcases robust performance. We can clearly see the predictive power of transfer learning, and approaches like these are becoming increasing popular in the pharmaceutical industry where larger datasets are scarce. By training on more epochs and tasks, we can probably boost the accuracy as well!
Lets evaluate the model on one last string from ClinTox's test set for toxicity. The model should predict 1, meaning the drug failed clinical trials for toxicity reasons and wasn't approved by the FDA.
# Lets input a molecule with a toxicity value of 1
predictions, raw_outputs = model.predict(['C1=C(C(=O)NC(=O)N1)F'])
INFO:simpletransformers.classification.classification_utils: Converting to features started. Cache is not used. INFO:simpletransformers.classification.classification_utils: Saving features into cached file cache_dir/cached_dev_roberta_128_2_1
0%| | 0/1 [00:00<?, ?it/s]
print(predictions)
print(raw_outputs)
[1] [[-4.546875 4.83984375]]
The model predicts the sample correctly! Some future tasks may include using the same model on multiple tasks (Tox21 provides multiple tasks relating to different biochemical pathways for toxicity, as an example), through multi-task classification, as well as training on a larger dataset such as HIV, one of the other harder tasks in molecular machine learning. This will be expanded on in future work!
Congratulations! Time to join the Community! ¶
Congratulations on completing this tutorial notebook! If you enjoyed working through the tutorial, and want to continue working with DeepChem, we encourage you to finish the rest of the tutorials in this series. You can also help the DeepChem community in the following ways:
Star DeepChem on Github ¶
This helps build awareness of the DeepChem project and the tools for open source drug discovery that we're trying to build.
Join the DeepChem Gitter ¶
The DeepChem Gitter hosts a number of scientists, developers, and enthusiasts interested in deep learning for the life sciences. Join the conversation!